ImagePullBackoff

Hello all.
I need some help on this problem.
So, I'm using Ubuntu 16.04 and have one master and one worker.
My master node ip is 192.168.0.35
My worker node ip is 192.168.0.36
Both have static bridge enp0s3 connection, gateway 192.168.0.1, dns 8.8.8.8.
I changed my coredns pod configMap before.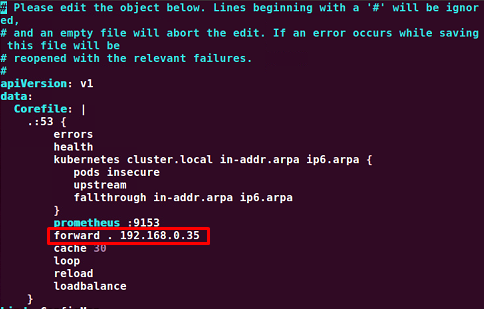
There was an error which ImagePullBackoff status when i tried to pull image from docker to make a pod, but this only happened on my master node. On my worker node, all worked fine, no error and got running status. But this matter will be solved when i restart the master node, may it one times or more until all pods were running. After restart one times or more, i got running status on all pods.
Anybody know why did this happen? Is there a problem with my network configurations?
Comments
-
Several master node restarts forced your pods to receive new IP addresses, probably until there was no more overlap in IPs with your nodes' IPs. In multi-node clusters, on the first node, the calico network plugin will assign IPs to pods from the 192.168.0.X subnet, on the second node the plugin will assign IPs from 192.168.1.X, on a potential third node from 192.168.2.X, ... - provided your calico was started with its default configuration. Keeping this in mind, I would see how IPs of pods running on the master node and the IPs of your nodes would overlap, considering both ranges are on 192.168.0.X, causing DNS confusion.
Regards,
-Chris0 -
I will make it more details.
Master node IP 192.168.0.35/24, hostname master
Worker node IP 192.168.0.36/24, hostname ubuntu
Both are static IPs, bridge enp0s3, gateway 192.168.0.1, dns 8.8.8.8
Calico is using the default, which is 192.168.0.0/16, i did not change anything
Also, master node and worker node both has same docker0 bridge IP which is 172.17.0.1/16
Actually, i'm wondering is it okay if both of my nodes have same docker0 with same IP?This is my cluster info

This is my /etc/hosts on master

This is my /etc/hosts on worker

When i ran docker run on my worker, it worked fine. But when i ran docker run on my master, i got this error

The command i ran before i got the error are
- kubectl apply -n sock-shop -f complete-demo.yaml
- kubectl get pods -n sock-shop -o wide

This is the pod that got the error
1. payment-7d4d4bf9hb4-hgbrx


2. queue-master-6b5b5c7658-rr5gb


Do you reference about Exercise 3.1 from number 8 until number 10?
Am i having Network Issues because of how i configured my network?0 -
Hi @neirkate,
Thank you for all the details provided. There seem to be several issues related to a misconfigured cluster. As mentioned earlier the default pods IP range 192.168.0.0/16, used by calico and the kubeadm init command, overlap the node IPs configured by your hypervisor. To fix this issue the suggestion was to rebuild the cluster and use different IP ranges: either change the IPs assigned to your nodes by the hypervisor or change the calico.yaml file and issue kubeadm init command with a different IP range for pods.
There also seems to be some naming confusion between the ubuntu node and worker node. It seems that pods are scheduled on a node named ubuntu when they should be running on the worker.
I agree with the suggestion of starting clean from 2 new nodes, and re-install all the components and re-create the cluster, by making sure there is no overlapping between nodes' IP range and pods' IP range. Both nodes should have the same type of networking interface, with promiscuous mode set to allow-all traffic.Good luck,
-Chris0 -
@chrispokorni
Sorry for the late reply.
I just knew it that i had configured my cluster wrongly, especially the network part.
Okay, i will do that. Seems like that is the best solution for this problem.
Thank you for your help.Have a nice day.
0

Categories
- All Categories
- 177 LFX Mentorship
- 177 LFX Mentorship: Linux Kernel
- 750 Linux Foundation IT Professional Programs
- 373 Cloud Engineer IT Professional Program
- 169 Advanced Cloud Engineer IT Professional Program
- 74 DevOps IT Professional Program - Discontinued
- 4 DevOps & GitOps IT Professional Program
- 99 Cloud Native Developer IT Professional Program
- 7.6K Training Courses & Learning Paths
- 1 AI & ML Training
- 1 Blockchain & Decentralized Identity Training
- 3 Cloud & Containers Training
- 1 Cybersecurity Training
- 2 DevOps & Site-Reliability Training
- 1 Linux Kernel Development Training
- 1 Networking Training
- 1 Open Source Best Practice Training
- 1 System Administration Training
- 1 System Engineering Training
- 1 Web & Application Development Training
- 792 Hardware
- 202 Drivers
- 68 I/O Devices
- 37 Monitors
- 95 Multimedia
- 173 Networking
- 91 Printers & Scanners
- 87 Storage
- 769 Linux Distributions
- 81 Debian
- 68 Fedora
- 22 Linux Mint
- 13 Mageia
- 24 openSUSE
- 150 Red Hat Enterprise
- 31 Slackware
- 13 SUSE Enterprise
- 356 Ubuntu
- 465 Linux System Administration
- 31 Cloud Computing
- 73 Command Line/Scripting
- Github systems admin projects
- 98 Linux Security
- 78 Network Management
- 101 System Management
- 46 Web Management
- 106 Mobile Computing
- 18 Android
- 73 Development
- 1.2K New to Linux
- 1K Getting Started with Linux
- 392 Off Topic
- 121 Introductions
- 181 Small Talk
- 29 Study Material
- 955 Programming and Development
- 310 Kernel Development
- 627 Software Development
- 983 Software
- 375 Applications
- 182 Command Line
- 5 Compiling/Installing
- 68 Games
- 317 Installation
- Archived
- 2 LFD140 Class Forum
Upcoming Training
-
August 20, 2018
Kubernetes Administration (LFS458)
-
August 20, 2018
Linux System Administration (LFS301)
-
August 27, 2018
Open Source Virtualization (LFS462)
-
August 27, 2018
Linux Kernel Debugging and Security (LFD440)